Since the turn of the century, technology has evolved rapidly, and we now live in a digital society that is soon to be transformed again through artificial intelligence. This rapid evolution has both advanced and hindered many businesses, as they now have a wider range of resources to provide greater services but are struggling to keep up with the demands of running these new innovations. This is particularly true of data, with a study showing that 59% of businesses are worried that their organizations’ ability to manage data won’t meet GenAI’s demands without significant investment. This data concern has led to a demand for data management systems that are able to seamlessly store and organize not only the increasing amounts of data but also the new types of data that modern technology is producing. One data management system that institutions across industries are investing in is a vector database.
What is a Vector Database?
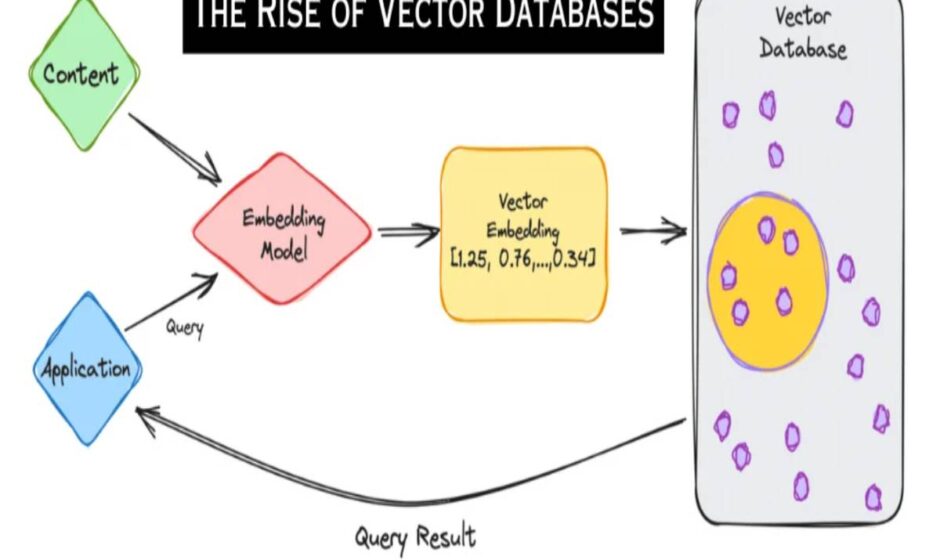
Unlike a traditional database, a vector database stores data in a multi-dimensional space on vector embeddings (also known as vectors). The inputted data is converted through an embedding model and stored in a vector index. This not only allows for the effective storing of vast amounts of different data types, most notably unstructured data, but also allows computer programs to read the data to make comparisons, detect relationships, and even understand context. Vector databases will cluster related data points to enable large-scale similarity searches and power AI models such as large language models (LLMs). They are able to do this by storing data on vectors.
What is a Vector?
A vector is a quantity with both magnitude (or size) and direction that can be broken down into components. In a vector database, the vector is an embedding – a list or sequence of numbers representing any data type. This includes unstructured data (data without a pre-defined data model or schema), ranging from text, documents, and social media posts to audio, image, and video files.
How Does a Vector Database Store Data?
Using the above image, we will examine how a vector database could hold a large collection of animal images. Each animal image is inputted into an embedding model, an algorithm that converts the data into a list of numbers to become a vector embedding. Data points included in this embedding can include the type of animal, the number of animals in the photo, and the color of the background. The embedding is then stored in the vector database in a three-dimensional space. In this space, all the animal images that are related to each other would be clustered together. For example, images of a lion, a tiger, and a cat are all part of the cat family and would be clustered together. If there are images of dogs in the collection, they would be situated near images of cats because they are both domestic pets. These groupings allow for an instant similarity search.
What is a Similarity Search?
After the data has been converted into an embedding, the embedding is then stored in a vector index, which groups all the clusters together to allow for a similarity search. For example, if the user inputs a search query for the term cat, all images related to cats will be retrieved. The user can narrow the search by inputting more detailed queries for the images they want. Most databases use a k-nearest neighbor (kNN) search, which will only look for exact or as close as possible matches. A similarity search in a vector database uses the approximate nearest neighbor (ANN) approach. An ANN search casts a much wider net for any result related to the query. An ANN is a much more effective way to search for relevant data points in datasets with millions, even billions, of data points.
How are Vector Databases Applied in the Real World
There are many applications that can use vector databases, with one of the most popular being personalized recommendations. Let’s take an online movie streaming service as an example. A vector database can be used to store viewer histories, grouping together the similar films that they have watched and recommending similar films that are related to those films. When you get recommendations for e-commerce platforms, the same technology is used. Another popular usage for vector databases is the training of LLMs. The vector database for an LMM will have embeddings that encapsulate semantic meanings and relationships between words or phrases. Taking Chat GPT as an example, a user would pose a question; the application would then convert the question into an embedding and perform a semantic search against the vector database using a similarity search to find the most relevant embeddings. The top 3 or 4 results from this search are then passed to the Chat GPT, which generates a response based on these results, providing the user with a detailed answer based on the knowledge base.
If you are looking for more guides on the latest technology, please visit the rest of our site.